
Rédacteur : Trance
Date de création : 30/06/2006
Section : Sécurité > Reversing
Imprimer cet article : en noir et blanc ou en couleurs
Ceci est la retransciption de ma toute première conférence donnée dans mon école. Elle introduit la sécurité informatique et plus particulièrement le reversing, pour les débutants. Vous y apprendrez les bases afin de savoir comment, en gros, se reverse un programme. Nous verrons les différents types de programmes qui existent, et nous nous attacherons aux programmes compilés.
La sécurité informatique est l’ensemble des moyens techniques, organisationnels, juridiques et humains nécessaires pour conserver ou rétablir la disponibilité, l'intégrité et la confidentialité des informations ou d'un système d'information (source : Wikipédia). En clair, c'est la discipline qui vise à étudier et à corriger les vulnérabilités des systèmes informatiques. C'est aussi une méthode pour apprendre énormément de choses sur l'informatique, et qui permet aux futurs programmeurs de programmer « proprement » en éliminant les sources de conflits dans les programmes.
Les domaines auxquels elle s'applique sont très variés. Il peut s'agir de l'étude des virus, des réseaux, des protocoles, des failles de sites web, ... et même du facteur humain, chose qui n'est absolument pas à négliger.
Le raisonnement très souvent appliqué dans la sécurité informatique est le suivant :
Nous allons nous intéresser plus particulièrement à l'étude des programmes et de leurs moyens de protection. Ce domaine s'appelle le « Reverse Engineering », contracté en « Reversing ».
Le Reversing est la mise à l'épreuve des sécurités d'un programme, ainsi que l'analyse de son fonctionnement. « Reverse Engineering » signifie « Ingénierie Inverse » ce qui est assez révélateur : l'ingénieur code un programme et le compile, le reverser fait le chemin inverse à savoir l'analyse du code binaire du programme pour remonter à son comportement et éventuellement ses sources. En fait, le reverser considère le programme comme une « boite noire » (puisqu'il n'en possède souvent pas les sources) et l'étudie de l'extérieur.
On rappelle que la pratique du reversing est très souvent interdite par la licence des logiciels propriétaires. Il faut donc lire la licence d'un programme avant de le reverser...
Afin d'illustrer cet exposé nous allons nous mettre dans la situation suivante : On considère que l'on dispose d'un programme sans ses sources. Ce programme possède un moyen de protection assez primitif, à savoir une vérification de mot de passe. Suivant le code entré, le programme aura un comportement différent. Notre but va être de trouver le code « déverrouillant » le programme.
Mais il faut rappeler ce que l'on entend par « programme ». En effet, il existe différents types de programmes et leur comportement sera nettement différent selon leur nature. Tous les programmes ne s'étudient donc pas de la même manière.
Lorsque l'on code un programme, le code source du programme subit des transformations avant d'être exécuté par le processeur. La « chaîne de compilation » est le processus suivi par le code source pour arriver jusqu'au code binaire. Elle est résumée par les étapes suivantes :
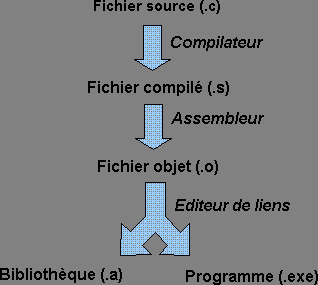
Chaîne de compilation d'un programme
En pratique, lorsque l’on compile un programme, toutes ces étapes se font avec le même logiciel (par exemple gcc) donc on ne s’en préoccupe que rarement. Mais comprendre le fonctionnement de la chaîne de compilation est indispensable dans la suite.
Le programme résultant ne contient pas uniquement des instructions exécutées par le processeur lors de son lancement. Il contient également tout un tas d'informations regroupées dans ce que l'on appelle des « sections ». Lorsqu'on lance le programme (le classique « double-clic » sous Windows), le système d'exploitation charge le programme en mémoire. Ce processus étant assez complexe, on peut simplement considérer qu'il recopie le code du programme dans la mémoire virtuelle (RAM). Puis le processeur exécute de manière linéaire la partie instructions du code.
Afin de comprendre davantage le fonctionnement de l'exécution d'un programme, des bases en assembleur sont indispensables. Cependant pour avoir une vision simplifiée des choses, on peut se contenter d'un petit condensé de notions d'assembleur.
J’en profite pour préciser que n’étant pas spécialiste en la matière, il se peut que toutes les informations données ici (et dans toute la conférence) ne soient pas exactes à 100%. Si jamais vous constatez un écart avec la réalité, n'hésitez pas à me mailer afin que je corrige ce document.
Entrons dans le vif du sujet. Le processeur ne peut exécuter du code que si celui-ci est chargé en mémoire. Un programme est donc chargé en mémoire avant de voir son code exécuté. La mémoire (virtuelle) allouée pour un programme est décomposée en plusieurs parties. Le code binaire du programme sera chargé à un endroit précis de cette mémoire. Puis il y a d'autres parties de la mémoire qui vont contenir des données. Celle qui nous intéresse particulièrement est la pile (« stack » en anglais). C'est une zone qui va par exemple contenir les chaînes de caractères, les tableaux, pointeurs, etc... c'est à dire les données de taille importante que le processeur ne sait pas manipuler seul. La pile est une structure de donnée qui porte bien son nom puis que les données qu'elle contient sont « empilées » et « dépilées ». Lorsqu'on veut placer une chaîne de caractères sur la pile, on l'empile donc elle se retrouve au sommet ; si on veut empiler davantage de données, elles seront placées « au dessus ». Si on dépile, ce sera la dernière donnée placée qui partira en 1er, puis au tout de l'avant-dernière, etc... C'est le système LIFO : « Last In, First Out » ou « Dernier arrivé, premier sorti ».
Toutes les zones mémoires sont adressées, c'est à dire qu'on peut y accéder en connaissent leur adresse, codée sur 4 octets. Cela représente 256^4 valeurs ; une pour chaque octet adressé, soit 4Go de mémoire. Il faut également savoir que sur les architectures x86, que la plupart de nos ordinateurs utilisent, la pile « croît vers les basses adresses » ; c'est-à-dire que le bas de la pile a une adresse plus élevée que son sommet. Ceci permet, en compensation du système LIFO, d’obtenir un arrangement « de haut en bas » de la mémoire consacrée à la pile, et est plus simplement facile à comprendre. Imaginez une pile d'assiettes suspendues au plafond ; leur hauteur est comparable à leur adresse. Par exemple, si un élément 1 est empilé sur la pile en 1er et qu’un élément 2 est rajouté, l’adresse de 2 sera plus petite que celle de 1, mais 1 sera en dessous de 2 par rapport à la pile ; 2 est au sommet de la pile.
Registres. ESP.Pour se repérer dans la mémoire, le processeur dispose d'un certain nombre de « registres » qui sont des zones de sa propre mémoire. Ils sont situés dans le processeur même et sont totalement indépendants de la pile ou des autres zones mémoire. Ces registres ont une fonction assez précise et portent tous un nom. Certains servent à effectuer des opérations algébriques, d’autres contiennent des adresses, par exemple. Celui qui va nous intéresser ici est nommé ESP (Extended Stack Pointer). En effet, c'est un registre qui pointe toujours vers le sommet de la pile, c'est à dire qu'il contient l'adresse du dernier élément empilé de la pile.
Le code binaire du programme est en fait du « langage machine ». On peut le représenter sous forme binaire, ou dans une autre base : octale, décimale... mais la plus adaptée étant l'hexadécimale. Sous cette forme, chaque octet occupe deux 'caractères' au sens habituel, et allant de 0 à 9 et de A à F. C'est à dire que tout nombre compris entre 0 et 255 se situera entre 00 et FF en héxadécimal. De plus, chaque instruction dans ce langage se traduit par une instruction en langage Assembleur. L'assembleur est en quelque sorte une interprétation du langage machine pour faciliter sa programmation. Il est donc possible de coder directement un programme en langage assembleur ou en langage machine...
Foncions.La dernière notion qui va ici nous être utile est le concept de « fonction ». Lorsque l'on code, on écrit rarement son code de façon linéaire sous la forme d'un seul programme ; on a plutôt tendance à le fragmenter en fonctions. En assembleur, les fonctions existent également et sont même très utilisées. Lorsqu'on veut appeler une fonction, on place ses arguments sur la pile dans l'ordre inverse. Puis on exécute l'instruction assembleur « Call » suivie de l'adresse relative de la fonction. Par exemple « Call 0x80482f0 » signifie « appeler la fonction située à 0x80482f0 octets de cet appel (le préfixe ‘0x’ signifiant ‘représentation hexadécimale’) » . Le retour d'une fonction, habuelement codé par "return" dans un langage de plus haut niveau comme le C, est interprété par l'instruction « RET ». En réalité, dans chaque fonction se trouvent un prologue ainsi qu'un épilogue, mais nous verrons cela une prochaine fois.
Ce sera tout pour les notions d'assembleur. Ce sont des notions difficiles à assimiler et qui demandent du temps avant d'être bien comprises. Je n'ai pas l'intention de faire un cours sur l'ASM dans ce document, vu que c'est une sorte de présentation du Reversing. En attendant que j'en fasse un, je conseille fortement aux intéressés de se documenter sur le sujet pour que les choses soient plus claires. Je donne tout en bas une liste de documents utiles et très intéressents.
Nous avons vu le cas des programmes compilés dont le code est exécuté par le processeur. Il existe d'autres langages, comme Java, dont le code n'est pas exécuté par le processeur mais par un autre programme qui va interpréter ce code en langage machine compréhensible par le processeur. Le programme qui sert d'intermédiaire et qui interprète le code est appelé « Machine Virtuelle » (abrégé VM pour « Virtual Machine »).
Le principal avantage de cette exécution est la portabilité. En effet, tout programme écrit dans ce langage sera exécutable sur n'importe quelle plate-forme et OS pourvu qu'il existe une machine virtuelle (qui, elle, sera différente) pour l'OS ou la plate-forme considérée. Ses principaux inconvénients sont le manque de contrôle sur le système ainsi que les données manipulées. La lenteur d'exécution en est également un point faible.
Ce type de programme n'est pas compilé mais directement exécuté par un « Interpréteur » qui est un logiciel un peu comparable à une VM qui interprète le code source en langage machine. La portabilité est là encore un atout, et la lenteur un inconvénient.
Nous avons à présent les types de programmes les plus répandus, et nous allons maintenant nous intéresser aux outils qui nous permettrent de les étudier.
Si vous êtes du genre curieux, vous avez sûrement déjà tenté d'ouvrir un programme compilé à l'aide d'un éditeur de texte. Et voici ce que vous y avez vu :
En effet, le programme étant de nature binaire, l'éditeur de texte transcrit son code en caractères, ce qui n'est pas très lisible pour un humain. Pour éviter cela, on utilise un éditeur hexadécimal, qui n'effectue aucun traitement sur le code et qui l'affiche tel qu'il est dans le fichier :
Il faut admettre que c'est tout de même mieux. Même si cela a l'air à première vue tout aussi incompréhensible, c’est au moins lisible. On peut citer de nombreux logiciels qui font ce travail comme WinHex sous Windows ou HexEdit sous Linux.
En réalité, le code que l'éditeur héxadécimal affiche contient le code en langage machine du programme. Lire un tel langage étant vraiment difficile, il existe un outil permettant d'afficher son équivalent en assembleur.
« Assembler » un programme signifie transcrire son code assembleur en langage machine. Vous aurez compris que « Désassembler » est l'opération inverse. Cependant, un désassembleur se contente rarement de transcrire ce que l'on voit dans un éditeur hexadécimal en assembleur puisque parmi ce code il y a des informations qui n'ont rien à voir avec de l'assembleur. En fait, un désassembleur charge d'abord le programme en mémoire puis lit la partie instructions en la transcrivant de la sorte :
La colonne de gauche contient l'adresse mémoire des instructions, celle du milieu les instructions en langage machine (que l'on peut voir avec l'éditeur hexadécimal) et celle de droite les instructions en assembleur.
Sous Linux, on peut utiliser gdb ou objdump et sous Windows, OllyDbg.
Le débogueur, comme son nom l'indique, sert au départ à éliminer les bogues de ses programmes. Il permet de tracer le comportement d'un programme, de poser des « breakpoints » (c'est à dire d'arrêter temporairement le programme) et d'examiner tout un tas de paramètres dont la mémoire et les registres. C'est un outil très puissant pour tout reverser ou programmeur. Un reverser peut s'en servir pour modifier le comportement du programme en le figeant à l'aide d'un breakpoint et en modifiant ses variables alors que le programme reste gelé.
Sous Linux, gdb reste une référence, ainsi qu'OllyDbg, ou Windasm sous Windows.
Un même logiciel peut servir à la fois d'éditeur hexadécimal, de débogueur et de désassembleur, ce qui constitue un outil redoutable.
Notez qu'il existe un tas d'autres logiciels de diagnostic de programmes. on peut citer par exemple strings sous Linux qui liste les chaînes de caractères que contient un programme (il doit sûrement exister un équivalent sous Windows mais je n'ai pas cherché).
Maintenant, nous avons tout ce qu'il faut pour entamer la pratique...
On se place dans la situation que nous avons déjà évoquée : nous souhaitons découvrir le mot de passe pour déverrouiller un programme en supposant que nous n'ayons pas les sources. Afin de rester dans le cadre légal et pour simplifier les choses, nous allons reverser des programmes faits maison...
Que ceux qui ne connaissent pas le Python se rassurent, il est très rapide de se familiariser avec un tel langage. Nous allons coder le programme suivant, nommé test.py : (Ici on utilise Linux. Pour les utilisateurs de Windows, il suffit d’enlever la 1ere ligne du code)
Ici, une chose est frappante. Comme un programme interprété n'est pas compilé, sa source est directement accessible en éditant le fichier. Inutile de s'embêter, il suffit de savoir lire pour trouver le mot de passe...
Passé les hors d’½uvres, on passe à quelque chose de plus sérieux...
Rappelons-le, un programme java est compilé puis exécuté avec une machine virtuelle. Editer le fichier ne servira donc probablement pas à grand chose...
Codons et compilons le programme suivant nommé test.java :
On compile avec javac test.java et on exécute avec java test. On obtient :
Cela signifie qu'il faut utiliser le programme en lui passant un paramètre en argument. Essayons donc : (remarquez que '$> ' symbolise juste l'invite de commandes)
Dommage. On va donc utiliser nos talents de reverser pour découvrir le mot de passe.
Java nous fournit des utilitaires qui ne se limitent pas aux programmes java et javac. Il y a entre autres jdb, et javap. Jdb permet de déboguer un programme, de lister des informations, et de le désassembler.. Voyons voir :
On obtient un invite de commande. On tape help pour en savoir plus. Cela nous liste les options disponibles. Parmi elles on note « run » qui permet de lancer le programme, « stop in » pour poser un breakpoint, et « list » pour lister le code source. On commence par placer un breakpoint au début du programme, dans le main ; comme cela lorsqu'on lancera le programme, il ne quittera pas.
J'ai commenté les lignes que l'on obtient à l'écran pour plus de compréhension.
Nous voyons que nous pouvons lister le code à volonté... Comment cela se fait-il puisque le programme est compilé ? En fait, lorsque l'on compile avec javac, il existe une option qui permet d'inclure ce que l'on appelle les « symboles de débogage » qui sont entre autres un lien vers les ligne du code source. En effet, selon mes tests, cela ne marche que si le code source .java reste dans le dossier du .class. Par défaut, il me semble que cette option est activé dans javac. Pour compiler sans ces symboles, il faut rajouter ceci à la ligne de commande lorsque l'on compile : -g:none . Plus simplement, si vous ne voulez pas que l’on puisse lister le code il faut éviter d’avoir la source dans le même dossier...
Pour le moment, c'était facile... On va tenter de recommencer mais en corsant la difficulté ; on va compiler sans inclure les symboles de débogage dans le programme.
On peut retenter la même chose avec jdb (je vous laisse le refaire si vous voulez vous entraîner) mais on constatera vite que la commande « list » ne marche plus :
Cependant, il existe d'autres utilitaires (non fournis par Java) comme Jad (The Java Decompiler), qui permet de reconstruire le code source d'un programme .class. Il suffit de le télécharger et de le tester :
Maintenant, éditez le fichier test.jad créé.
Nous avons alors la surprise de voir que le code source du programme a été reconstitué, à peu de choses près. Et si vous le compilez, il marchera exactement de la même façon que le programme original...
La parade pour empêcher cette décompilation est encore inconnue à ce jour. Mais vous pouvez retarder un reverser éventuel en faisant appel à un programme qui vous rendra votre source « crade » et incompréhensible en mélangeant les noms des fonctions. Je n’ai jamais testé cette méthode donc je n’ai pas d’expérience sur ce sujet.
Retenez cependant que si vous êtes un jour développeur et si vous voulez conserver vos secrets, n'optez pas pour Java... à moins d’avoir une barrière anti-reversing solide.
Jusqu'ici, rien de bien difficile puisque dans tous les cas de figure nous avons pu lire le code source du programme reversé. Mais dans ce cas, ce ne sera pas possible dans le cas général. Cela commence à devenir du « vrai » reversing !
Attention, les choses deviennent plus difficiles. Si vous ne comprenez pas tout, ce n’est pas grave, essayez de suivre les idées directrices. Nous éclaircirons certainement les choses dans d’autres conférences. Mais en attendant, je vous conseille une fois de plus de vous documenter sur l'assembleur si vous voulez bien comprendre le cheminement suivi.
Notre raisonnement va être quelque peu analogue à celui utilisé jusqu'ici. Nous disposons d'un programme test.c que voici :
Rappelons-le, il n'est pas possible en C de comparer deux chaînes de caractères avec = = car cet opérateur ne compare que les adresses (comme en Java). La fonction utilisées est strcmp(char chaine1[], char chaine2[]) qui retourne 0 si les deux chaînes sont égales, et un nombre non nul si elles diffèrent. D'où l'intérêt du ! placé devant dans le code source.
On commence par compiler en incluant les symboles de débogage (option non mise par défaut : -ggdb) :
Libre à vous de tester le programme avec un mot de passe bidon. Passons au reversing. Nous allons utiliser deux outils : OllyDbg (Windows) et GDB(Windows et Linux).
OllyDbg est un des outils de référence pour le débogage et le reversing. L’outil, à la tradition de la plupart des logiciels Windows, est entièrement graphique. Voici à quoi il ressemble :
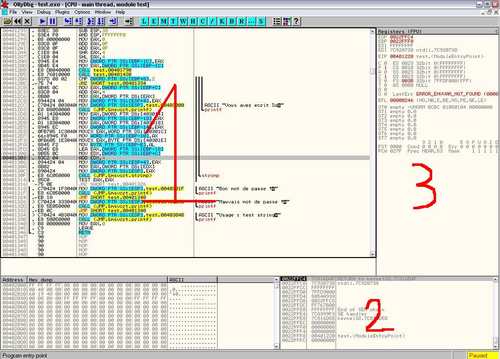
On ouvre le programme avec File > Open. Une fenêtre Dos s’ouvre, il ne faut pas la fermer puisque c’est à l’intérieur de celle-ci que s’exécute le programme test.
La fenêtre d’OllyDbg est fragmentée en plusieurs sections que j’ai numérotées. La zone 1 comporte plusieurs colonnes qui contiennent en partant de la gauche : l’adresse de l’instruction, le code en langage machine, le code désassemblé du programme, et quelques commentaires d’Ollydbg. La partie 2 représente la pile, zone mémoire dont nous avons déjà parlé, et la partie 3 contient les valeurs des différents registres du processeur.
Une fois le programme ouvert, allez dans Debug > Arguments, et tapez « aaaaaaaaaaaaaaaa » (la chaîne de caractères n’importe pas, du moment qu’elle est facilement reconnaissable). Puis validez. Nous venons de modifier les arguments passés au programme. Pour que les paramètres soient pris en compte, il faut relancer le programme test, pour cela cliquez sur les deux flèches << en haut à gauche.
Dans la zone 1 on peut voir :
Le fameux appel à strcmp() se fait donc ici. Nous allons placer un breakpoint sur la fonction et regarder l’état de la pile. Pour placer un breakpoint, double-cliquez sur le code machine correspondant à la fonction (ici E8 6C050000 ). L’adresse passe en rouge. Pour enlever le breakpoint, la méthode est la même. Maintenant, lançons le programme avec F9.
Très vite il s’arrête à cause du breakpoint. Regardons de plus près la pile en bas à droite.
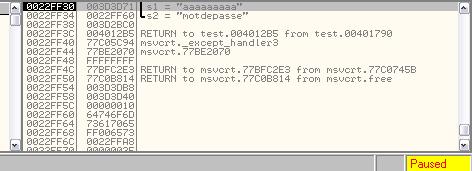
Je pense que l’image parle d’elle-même… On retrouve les deux arguments de strcmp au sommet de la pile (à l’adresse 22FF30) qui sont la chaîne entrée en argument du programme et le vrai mot de passe.
Nous avons ce que nous voulions avoir. Vous pouvez libérer le programme en appuyant sur F9 et quitter Ollydbg.
Gdb, alias « the Gnu Debugger », est un outil entièrement en ligne de commande. Mais il n’en demeure pas moins puissant puisqu’il fait partie des outils de références utilisés, surtout sous Linux. Si vous possédez l’environnement de développement DevC++ (Windows), il est déjà inclus. Sinon, vous pouvez le télécharger. Assez discuté, passons à l’action : (les // sont des commentaires)
Voici le code désassemblé de la fonction main. On peut à présent placer un breakpoint (comme pour le paragraphe précédent sur Java). Mais nous allons le placer non pas au début mais à l'adresse 0x08048429, ou main+117, c'est à dire l'endroit précis du programme où s'effectue la comparaison (ligne soulignée dans le listing ci-dessus). Allons-y :
Nous avons lancé le programme avec « aaaaaaaaa » comme chaîne de test, elle sera facile à repérer par la suite. Le programme s'est stoppé au breakpoint, comme prévu. On constate au passage qu'on voit le code source du programme. Pour le lister, on utilise list :
On pourrait s'arrêter là puisqu'on a accès au code source, mais nous allons continuer parce que nous sommes des curieux... De plus, si nous voulons reverser un programme quelconque, les symboles de débogage ne sont pas forcément inclus dedans (et même rarement...) . Voyons comment se débrouiller pour retrouver la chaîne de caractères qui nous intéresse (le mot de passe) dans la mémoire :
La méthode était relativement simple mais peut paraître complexe à première vue. Tentons de la clarifier.
av est un tableau de pointeurs. Ces pointeurs pointent vers des chaînes de caractères qui sont en réalité
les arguments passés en paramètres lors de l'exécution (comme args[] en Java). av[0] contient l'emplacement du programme sur
le disque ; av[1] le 1er argument (les aa...), av[2] le 2ème, etc... Si nous avons affiché le contenu de av avec les
fonctions « print » et « printf », c'est juste pour vérifier leurs valeurs et se familiariser avec gdb.
Ensuite, nous nous sommes intéressés à ESP, le pointeur de sommet de la pile. Comme il y a un appel à la fonction strcmp,
et que le programme y est arrêté, nous devons forcément avoir les arguments de cette fonction au sommet de la pile.
C'est pour cela que nous avons affiché son contenu avec la commande « x/nx addr » (qui affiche les n octets suivant
addr en mémoire). Rappelez-vous que sur les architectures x86, la pile croît vers les adresses basses. De plus, comme
les paramètres des fonctions sont empilés dans l'ordre inverse, on retrouve bien av[1] et str dans le bon ordre en partant
du sommet en en allant vers le bas de la pile (vers les adresses hautes). Voilà pourquoi nous avons affiché la chaîne pointée
par les 4octets se situant à l'adresse contenue dans ESP (0xbff9e460). Les 4 octets suivants forment l'adresse de la chaîne
que nous recherchons, et ces 4 octets se trouvent à l'adresse [ESP+4]. Nous l'avons affiché, afin de récupérer le mot de passe.
Une autre possibilité est de taper « x/16c [adresse] » pour afficher les 16*4 octets suivant de [adresse] sous forme de caractères.
Maintenant, vous comprenez certainement le lien avec notre test d’Ollydbg : nous avons fait la même chose avec les deux outils, même si nous sommes allés plus loin avec Gdb.
A présent, nous savons reverser un programme basique écrit en C. Dans notre exemple, nous avons inclus les symboles de débogage à des fins de compréhension, mais on peut très bien les enlever en recompilant (sans l'option -ggdb) et essayer de reverser le nouveau programme. Ce ne sera pas beaucoup plus dur : on ne pourra simplement plus afficher le contenu de av. Voici ce cela donne :
Nous sommes à présent capables de reverser un programme très basique écrit en C, qu'il comporte où non les symboles de débogage...
ous avons vu par la théorie et par la pratique comment il est possible de reverser des programmes de différentes natures. Nous avons pu trouver dans tous les cas de figure un moyen de casser la protection du programme.
Cette introduction au reversing illustre le principe suivant :
Il est impossible d'empêcher un reverser de comprendre le fonctionnement d'un programme par des mesures de protection logicielles.
C'est pourquoi, en pratique, on ne peut que retarder ou décourager un reverser. Et pour ce faire, nous avons vu qu'il faut :
La conférence avait pour objectif de sensibiliser le public à la sécurité informatique. Si vous êtes débutant, peut-être n'avez-vous pas tout compris ou tout suivi. Ceci est normal : le domaine de la sécurité informatique est très complexe et fait appel aux notions d'informatique les plus pointues, notamment dans le « bas niveau ». Et même si vous avez tout suivi, n’oubliez pas que cette conférence reste une simple introduction dans la matière. Pour arriver à reverser un programme de type complexe, il faut beaucoup plus de technique et encore plus de pratique.
Ici j’ai tenté de référencer tous les logiciels utilisés pour cette conférence. Ils sont tous gratuits. Si par malheur j’en ai oublié un, une petite recherche sur Google devrait vous permettre sans aucun problèmes de le retrouver.
Remarque : Si vous possédez une Debian ou une Ubuntu, la plupart des logiciels s’installent en tapant « apt-get install lenomduprog » dans un shell root. Sous Gentoo, l’équivalent est « emerge lenomduprog » .
Cette section est très courte, car pour écrire ce texte je ne me suis basé sur aucun cours particulier, juste sur mes connaissances... Voici donc un ou deux liens qui vous aideront peut-être...
